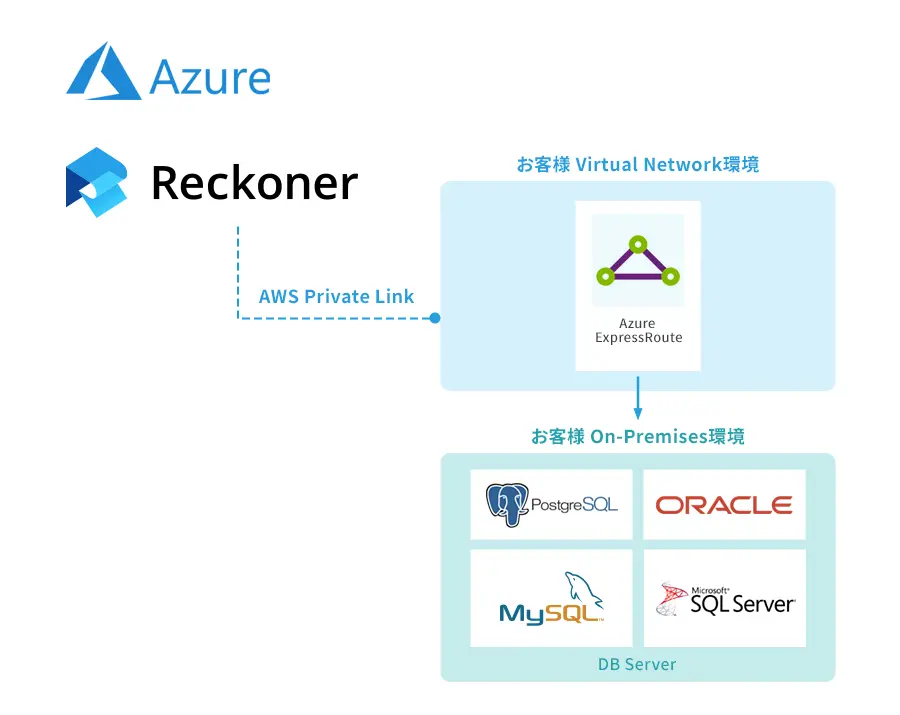
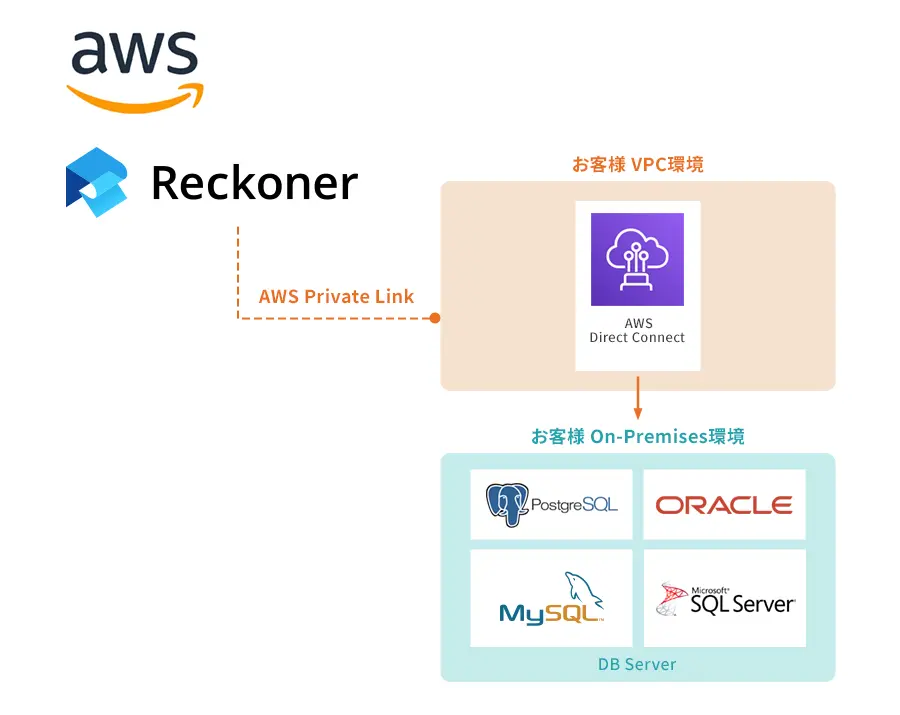
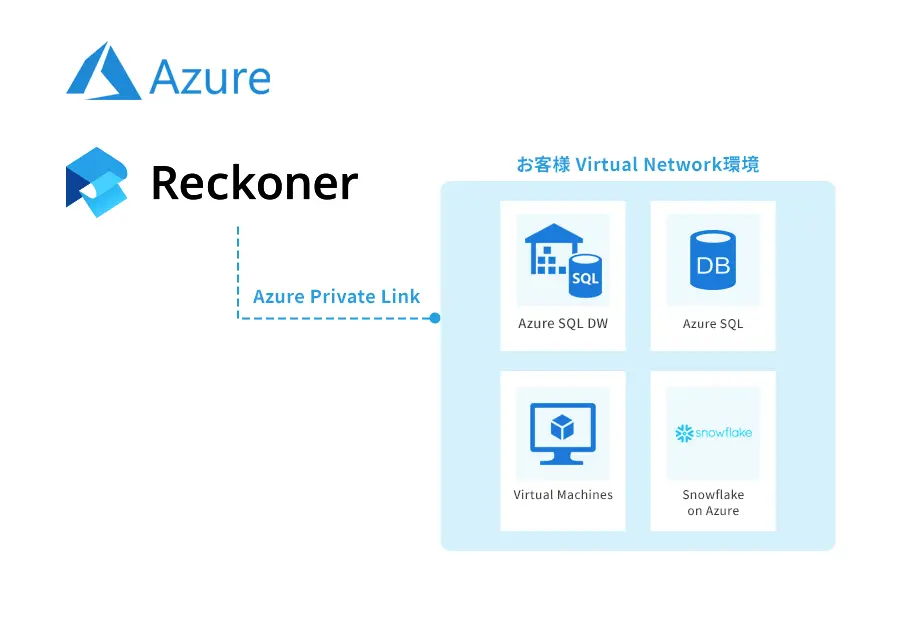
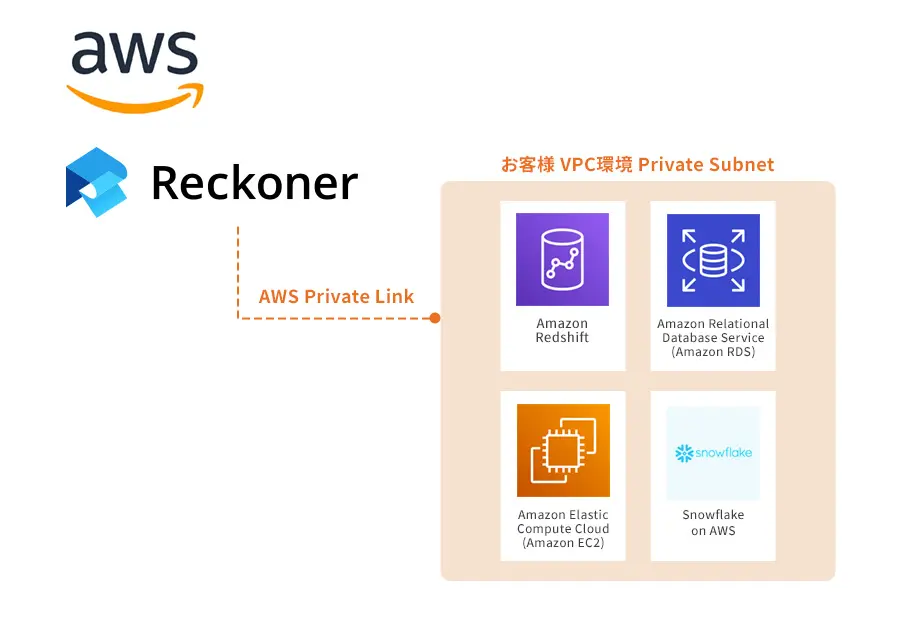
データ連携基盤とはなにか

「データ連携基盤」という言葉をよく耳にするようになりました。クラウドの活用が進んでいる昨今では、多くの企業でSaaSシステムの導入と共にデータ量も増加しています。そこで重要になるのがデータ連携基盤です。では、データ連携基盤はどのような意味があり、どのような価値をもたらすのでしょうか。以下で解説します。
目次
データ連携基盤とは

データ連携基盤とは、あるシステムに蓄積したデータを収集・加工し、そのほかのシステムへ連携して活用するための仕組みです。
データ連携基盤というと主に以下2つの意味を指すケースが多いです。
- 組織内の各種データを編集・共有するプラットフォーム
- 官庁や自治体などが、組織横断的にデータをやり取りするためのデータ基盤
それぞれの特徴を詳しく解説しましょう。
組織内の各種データを編集・共有するプラットフォーム
1つ目は、組織内に存在する各種データソースのデータを自動的に加工したり、組織内で共有したりすることを目的としたものです。
これは主に「組織内」または「グループ企業間」において、データを活用するための基盤を意味します。単一の企業組織内、グループ企業内のデータ連携に加えて、利用するSaaSなどのクラウドサービスとの連携が想定されます。
官庁や自治体などが、組織横断的にデータをやり取りするためのデータ基盤
2つ目は、官公庁や地方自治体などの公共組織で取り扱うデータを、横断的にやり取りし加工することで、データ処理を効率化することを目的としたものです。現在、デジタル庁がリーダーシップを持ち、基盤整備を進めています。
こちらに関しては、非常に大きな取り組みであることから、実際に利用できるようになるまでには、かなりの時間が必要となります。
以下では、「組織内の各種データを編集・共有するプラットフォーム」に関するデータ基盤連携について、具体的に解説いたします。
データ連携基盤で必要となる要素

データ連携基盤は、主に以下3つの要素が必要です。
- データの取得(自動抽出)
- データの編集(自動加工)
- データの出力(自動ロード・集計)
それぞれの観点を解説します。
データの取得(自動抽出)
データ連携基盤は、各データソースに接続し、必要となるデータを抽出するまでを自動化します。これにより、データ取得業務の効率化ならびに自動化が実現できるでしょう。
自動化をしなければ、データソースからCSVなどを抽出してデータ連携基盤へのインポート作業が必要となります。手作業で実施をすると、人的リソースが必要になるだけではなく、ヒューマンエラーが発生することでデータの信頼性が落ちてしまい、意思決定時に悪影響を及ぼす可能性があるでしょう。
データ連携基盤を構築するときは、データの取得を自動で実施することを前提にするのが望ましいです。
データの編集(自動加工)
続いて、複数のデータソースから取得したデータを、あらかじめ登録されているロジックに従い、必要な形に加工します。自動での加工により、工数削減とヒューマンエラーの削減が実現できるでしょう。
同じ意味のデータだったとしても、データソースが異なることで違ったデータとして解釈されることがあります。例えば、2つのデータソースで同じ顧客データを扱っていたとします。片方のデータソースでは顧客データの主キーを顧客番号としていましたが、もう一つのデータソースでは会社名と主キーと設定するケースもあります。これらのデータは、人間が見れば同じデータだと認識しますが、システム側では違ったデータと判断する可能性が高いです。そのため、同じデータと認識されるためにも、決められたロジックにしたがった加工が必要となります。
データの出力(自動ロード・集計)
自動で取得・加工されたデータは、そのデータを必要とする人や組織に共有しなければなりません。共有する工程をデータのロードと呼んでおり、データ連携基盤でも自動ロード・集計を実現します。
加工されたデータをそのまま見るためには、DBの知識が必要となるケースが多いため、情報システム部門など専門的知識を有した人材でなければなりません。そのため、ユーザーや組織全体が閲覧できる形にデータを集計し、プラットフォーム上で提供する必要があります。
こうしたデータを閲覧するプラットフォームは、BIツールとして提供されることが多いです。
データ連携基盤を利用すると得られるもの

データ連携基盤を利用すると、下記の効果が得られます。
- 信頼性
- 効率性
- コスト削減
それぞれの効果を解説しましょう。
信頼性
データ連携基盤は、あらかじめ定められたロジックにしたがって確実にデータを処理するため、信頼性の向上が期待できます。
人力でデータを処理すると、ヒューマンエラーが起こってしまい、そのエラーに気づかないと間違ったデータのまま処理が進んでしまいます。最終的には、重要な意思決定時に間違えた情報で判断をすることになってしまうでしょう。自動化していればヒューマンエラーはゼロになります。より信頼を高めるためには、データガバナンスについても検討が必要です。
効率性
データ連携基盤は、各処理が自動でされることによって人が時間を割いて作業しなくてもよくなるため、高い効率性が実現されます。
例えば、これまで1時間かけてデータの収集から出力までをおこなっていたとしたら、その1時間がそのまま不要となり、より価値の高い作業に時間を割けられるようになるでしょう。
つまり、データの処理に関する部分はデータ連携基盤で自動化をし、その後のデータをもとにした企業戦略の立案や業務改革などに注力していく体制が整います。
コスト削減
データ連携基盤の構築により、データ処理作業に時間をかけなくても良くなるということは、その作業で発生する作業費・人件費が不要になります。実際に、データ基盤の構築でかかるコストについて、下記の記事でまとめているので参考にしてください。
- 参考記事:データ収集基盤にかかるコストを考える
組織はコスト削減が実現できるため、そのほかに投資していくべき事業の拡大にコストを使っていけるでしょう。
EAIか、ETLか

組織において、データ連携基盤の実現するにあたり、大きく2つのアプローチがあります。それは「EAI」と「ETL」です。
| EAI | ETL | |
| リアルタイム性 | 必要 | (多くの場合) 必要ではない |
| 一度に処理するデータ量 | 少ない | 多い |
| トランザクション数 | 多い | 少ない |
EAIは、連携するシステム間のデータをリアルタイムで連携する基盤としての役割が期待されています。一例ですが、「自動車メーカーと部品メーカーで、現在の在庫状況や製造状況、発注数量などのデータをリアルタイムで連携したい」といった場合に有効です。一度に連携するデータ量は非常に少ないですが、一日に数万件以上のデータ連携が行われるのも一般的であるため、膨大なトランザクションを確実にさばく能力が求められます。
これに対してETLは、リアルタイム性が求められることはなく、多くの場合「一日一回、または複数回程度、大量のデータをバッチで効率的に一括処理する」基盤としての役割が求められています。例えば、「Eコマース企業が、一日に一度、各販売チャネルごとの売上データを抽出、加工したのちに、基幹システムに投入する」ような場合に有効です。トランザクション数は少ないですが、大量のデータを短時間で処理する能力が求められます。
このように、EAIとETLでは、そもそも求められる性質が異なるため、「EAIにすべきか、ETLにすべきか」と悩むケースは少ないでしょう。
データ連携基盤の構築は組織に大きなメリット
お伝えしてきたように、データ連携基盤の構築は組織にとって大きなメリットを与えます。データ連携基盤を実現する方法として、EAIとETLについて解説しましたが、ETL利用を検討する場合、当社が提供するクラウドETL「Reckoner」を用いることで、データ連携基盤の構築を短期間・低コストで実現可能です。
ETLツールは、データの取得・加工・出力を自動化できるため、データの信頼性・作業の効率性が向上し、コスト削減にもつながります。また、多数のデータベースやSaaSアプリケーションとの接続が可能で、シンプルなGUIによりノーコードですべてを完結できることも魅力的です。さらに、フルマネージドサービスでの運用となるため、運用工数がゼロとなります。
現在Reckonerでは無料トライアルを受け付けているため、今後ETLを新たに導入検討する企業はぜひご参考にしていただければ幸いです。
また、ETLツールについて詳しく知りたい、ETLツールの選び方を知りたいという方はこちらの「ETLツールとは?選び方やメリットを解説」をぜひご覧ください。