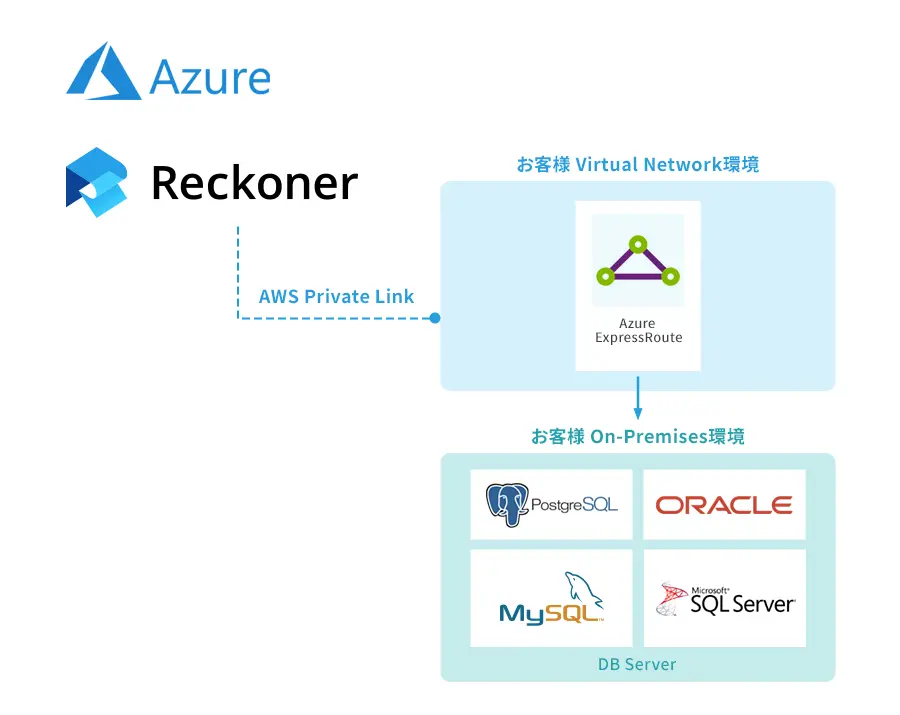
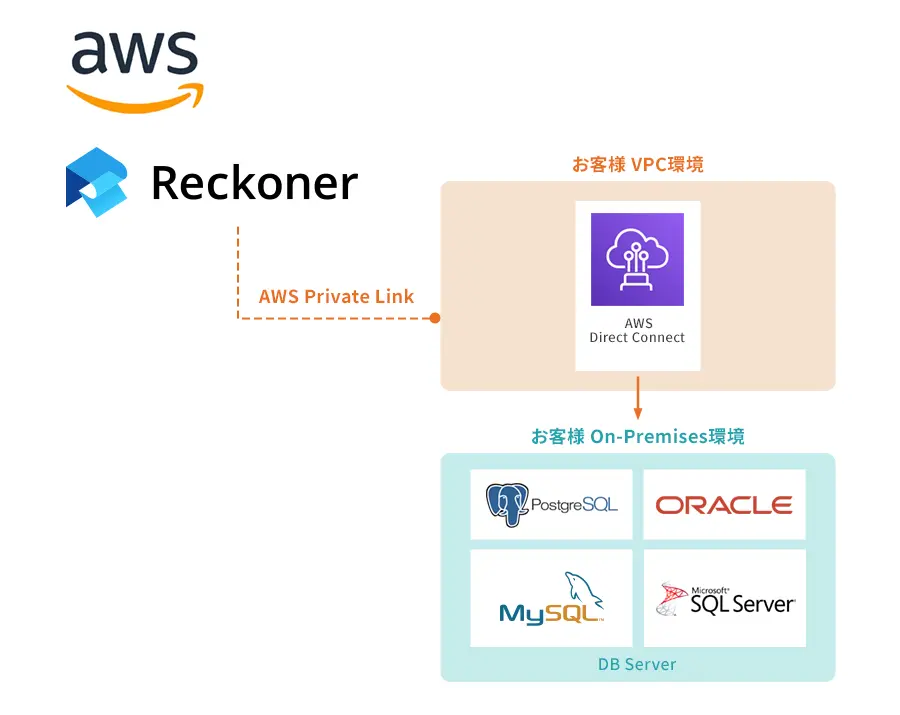
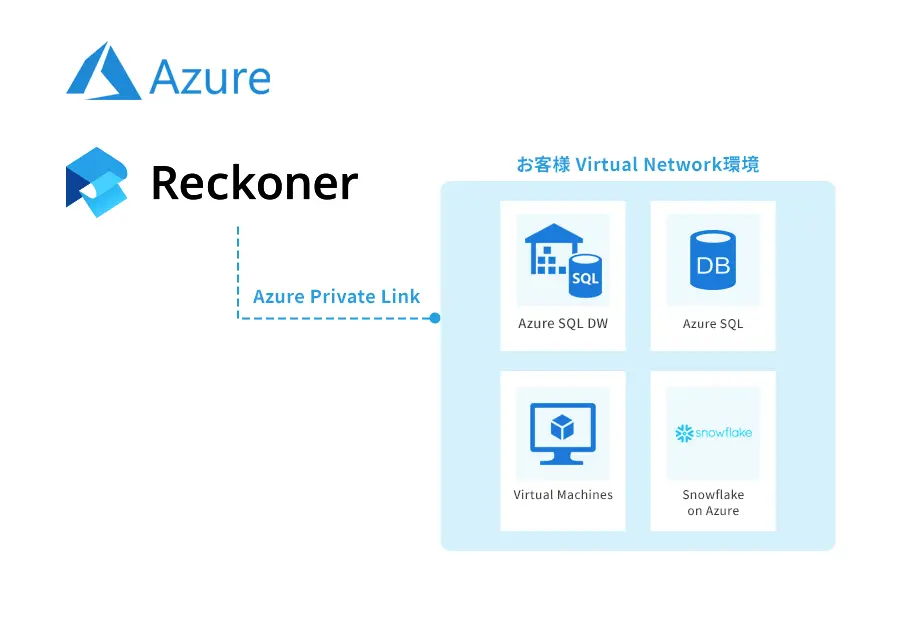
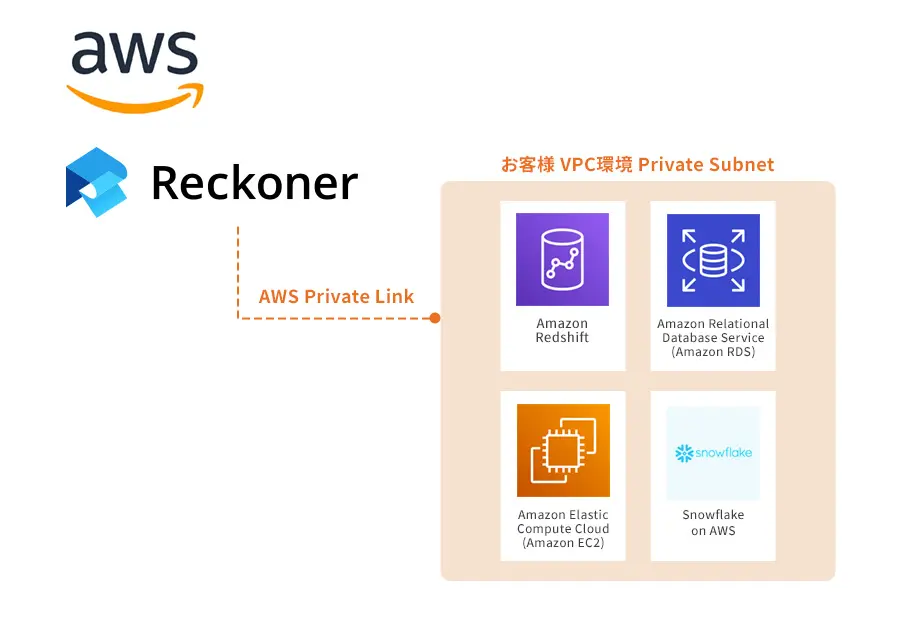
DevOpsとDataOpsの関連について理解する

DevOpsという思想の実践がSREであると一般ではよく言われています。では、DataOpsとDevOpsの関係はどのようなものでしょうか。
以下では、DevOpsとDataOpsの関連について解説します。
なお、以下の書籍を参考元とし執筆を行っております。
(参考元1:Davis, Jennifer, and Katherine Daniels. Effective Devops: Building a Culture of Collaboration, Affinity, and Tooling at Scale. Sebastopol, CA: O’Reilly Media, Inc., 2016.)
(参考元2:Nik Bates-Haus “Chapter 3. DataOps as a Discipline.” In Getting DataOps Right, edited by Palmer, Andy, et al., 13-27. Sebastopol, CA: O’Reilly Media, Inc., 2019)
目次
DevOpsの思想について理解する

DevOpsでは、以下のような手法ならびに環境が重視されています。
ウォーターフォールよりアジャイル
ウォーターフォールとは、大規模開発を秩序正しく進行することに重点を置いたプロジェクト管理プロセスです。これに対してアジャイルは、より軽量かつ柔軟なソフトウェア開発手法です。
アジャイルには、スクラムのようなプロセスや、コラボレーション、柔軟性、そしてソフトウェアの動作という最終結果に重きを置くその他の方法が含まれます。
スクラム
スクラムは、変化に迅速に対応する開発チームに焦点を当てたソフトウェア開発方法論です。
「スプリント」と呼ばれる開発サイクルを活用し、通常1週間から1ヶ月の期間で、目標を定義するスプリント計画会議に始まり、スプリントレビューとスプリントの振り返りで、発生した進捗と問題を議論して終了します。
ITIL/COBIT
ITIL(Information Technology Infrastructure Library)は、ITサービス管理のために定義されたプラクティスです。プロセス、手順、タスク、チェックリストなどのITIL遵守事項を確認し、改善を測定するために使用されます。
COBIT(Control Objectives for Information and Related Technology)は、ビジネスの目標とITの目標を一致させるために用いるフレームワークです。以下は、COBITの5つの基本原則です。
- ステークホルダーのニーズを満たす
- 企業を端から端までカバーする
- 単一の統合されたフレームワークを適用する
- 全体的なアプローチを可能にする
- ガバナンスをマネジメントから切り離す
リーン
リーン生産方式は、MIT(マサチューセッツ工科大学)の教授陣により作り出された概念です。
下記はリーン生産方式における 5 つの原則です。
- 価値の特定
- 価値の流れのマッピング
- フローの作成
- プルシステムの確立
- 完全性(継続的な改善)
上記のうち、無駄を体系的に特定・排除し、完璧さを追求することが、リーンの定義である「顧客価値の最大化と無駄の最小化」として用いられます。
バージョン管理
バージョン管理システムは、ファイルの変更を記録します。開発者は「コミット(commit)」「リビジョン(revision)」といった変更を行うと、誰がいつ変更したかなどのメタデータとともに、システム内に保存されます。
また、過去のリビジョンのオブジェクトをリポジトリにコミット、比較、統合、リストアする機能を用いることで、開発チーム内およびチーム間のコラボレーションを促進します。
アプリケーションのデプロイ
アプリケーションのデプロイとは、ソフトウェアリリースの計画作り、リリース実行、保守を含むプロセスを指します。
アプリケーション開発においては、インフラストラクチャの自動化を活用することで、リリースされるソフトウェアへの影響を最小化できます。
継続的インテグレーション (CI)
継続的インテグレーション(CI)は、新しいコードとマスターブランチを頻繁に統合するプロセスです。
ブランチとは、メインのプロジェクトと分岐したバージョンのリポジトリのことです。
マスターブランチとは、エンドユーザーがダウンロードできるようになったブランチです。
CIは、旧来の方法とは対照的です。つまり、「ブランチを数週間から数か月開発し、完成後にマスターブランチにはじめて統合」という方法ではなく、「小さな規模で頻繁に統合」が行われます。これにより、問題発生時の原因究明がより簡単になります。
継続的デリバリー (CD)
継続的デリバリー(CD)はソフトウェア工学の一般的な原則を集めたものです。自動テストとCIを活用して、高頻度のリリースを可能にします。
CDは、新しい変更が自動テストに逆行せずに統合できることに加え、これらの変更がデプロイされます。
MVP(minimum viable product)
MVPとは、製品のプロトタイプを必要最小限の機能、工数で作るという考え方です。
MVPは、100%の完成度を目指すものではなく、少ない時間と工数で作成し、製品の方向性を確認すること目的としています。
MVPによって、組織はコストと無駄を削減しながら、より迅速な反復と改善が可能となります。
構成管理
構成管理とは、機能や性能の一貫性を、ライフサイクルを通じて確立し維持するプロセスです。
このプロセスには、性能、機能、属性のシステムを実現するために必要な方針、プロセス、文書、ツールなどが含まれます。
クラウドコンピューティング
クラウドコンピューティングを活用したストレージソリューションは、オンプレミスのオーバーヘッドを削減できます。
クラウドの活用を通じ、コスト削減、開発速度向上に貢献します。イテレーション(一連の工程を短期間で繰り返すサイクル)と開発サイクルの短縮は、DevOpsの重要な要素です。
インフラストラクチャー自動化
インフラストラクチャー自動化とは、システムやサービスを管理する人の負担を減らし、消費者へのサービスの品質や正確さ、精度を高める方法です。
自動化は、繰り返しの手動作業を減らすことで、ミスを最小限に抑え、手動作業者の時間と労力を節約することを可能にします。
アーティファクト管理
アーティファクト(Artifact)とは、ソフトウェア開発プロセスにおけるアウトプットです。アーティファクトには、JAR(Javaアーカイブファイル)、WAR(Webアプリケーションアーカイブファイル)、ライブラリ、アセット、アプリケーションなどが含まれます。
アーティファクトは、組織に割り当てられた予算に応じてさまざまな方法で処理することができます。
コンテナ
ソフトウェアコンテナとは、OSやハードウェアから独立して開発・配備できる、分離された構造体です。
コンテナは、仮想マシンと同様に、その中で実行されるコードをサンドボックス化(外部から隔離された実行環境化)できます。また、仮想マシンと異なり、オーバーヘッドが少なく、OSやハードウェアへの依存度も低くなります。
このため、コンテナでアプリケーションを開発し、同じコンテナを本番環境に導入することが容易になりました。リスクと開発のオーバーヘッドを最小限に抑えながら、運用エンジニアに求められる作業量を削減できます。
レトロスペクティブ(プロジェクト終了後の議論)
レトロスペクティブ(retrospective)とは、プロジェクト完了後に、何がうまくいき、何が今後のプロジェクトで改善されるのか、といったテーマで行われる話し合いのことを指します。
レトロスペクティブは、一定期間経過後(四半期ごとなど)、またはプロジェクト終了時に行われます。
実施目的は、現場での学習、つまり、プロジェクトの成功や失敗を、将来の類似プロジェクトへいかに適用できるかという点となります。
ポストモーテム(インシデント発生後の共有・学習)
ポストモーテム(Postmortem)は、計画的で定期的に行われるレトロスペクティブと異なり、計画外の事故や障害発生後に行われます。
レトロスペクティブが計画的なのに対して、ポストモーテムはイベントが発生するまでは予期できません。ポストモーテムの目標は全社規模の学習です。
非難のない文化
非難のない文化は、たとえ自分の行動が直接否定的な結果につながったとしても、人々が安心してインシデントの詳細を報告・共有できるようにするためにあります。何がどののよに起こったのか、その詳細を知ることで初めて、学習が始まるのです。
(参考元:Davis, Jennifer, and Katherine Daniels. Effective Devops: Building a Culture of Collaboration, Affinity, and Tooling at Scale. Chapter 4. Foundational Terminology and Concepts. Sebastopol, CA: O’Reilly Media, Inc., 2016.)
DataOpsの実装について理解する

では、DataOpsではどうでしょうか。データエンジニアリングの専門家であるNikolaus Bates-Haus氏は、「Getting DataOps Right」にて、DataOpsの原則として以下の3つを挙げています。
- サーバーではなくサービス
- コードとしてのインフラストラクチャ
- 全てを自動化
これらを踏まえて、サービスとデータの可用性について簡潔に説明します。
サーバーではなくサービス
サービスをサーバーから抽象化することで、レプリケーション、エラスティック、フェイルオーバーなどの対応の幅が広がります。
これらを活用することで、個々のサーバーではうまくいかないような状況(突然の負荷急増など)にうまく対処することができます。
コードとしてのインフラストラクチャ (Infrastructure as Code, IaC)
インフラストラクチャのコード化により、インフラストラクチャの変更、コードの計画、テスト、バージョン管理、リリースなど、ソフトウェア開発で培った経験を活用できます。
IaCを用いると、サーバーのデプロイは適切なコードを実行するだけでよく、デプロイ工数や作業ミスを減少できます。
新しいデプロイメントで問題が発生した場合、問題に対処する間、デプロイメントをロールバックすることができます。このように、IaCを使用することで、予測可能で信頼性が高く、再現性のある運用が可能になります。
全てを自動化
需要が急増したとき、手動で新しいサーバーをデプロイする、手動がスクリプトを実行する必要があると、需要増への対応が遅れます。。
これらのプロセスは自動化される必要があります。自動化を通じ、小規模なDevOpsチームが大規模なインフラを効率的に管理し、迅速な対応を行うことができます。
以下は、DataOpsのプラクティスです。
- アジャイルプロセスの適用
- データを利用する社内顧客との統合チーム
- 全てコードで実装
- ソフトウェアエンジニアリングのベストプラクティスを適用
- 複数の環境を維持
- ツールチェーンを統合
- すべてをテスト
これらのプラクティスは、無数のエンジニアリングチームがタイムリーで高品質な製品を提供することを可能にします。こうした取り組みを通じ、データエンジニアリングチームが、高品質なデータをタイムリーに提供可能となります。
(参考元:Nik Bates-Haus “Chapter 3. DataOps as a Discipline. DataOps Tenets.” In Getting DataOps Right, edited by Palmer, Andy, et al., 13-27. Sebastopol, CA: O’Reilly Media, Inc., 2019)
まとめ
DataOpsは、データ領域において、DevOpsを強く受け継ぐ実践です。DevOpsおよびアジャイルに関して様々なポイントを理解し、念頭に入れておく必要があります。
DataOpsに関する理解を深めるために、弊社サイト内の関連記事「DataOpsとは?」をぜひ一読ください。
また、ETLツールについて詳しく知りたい、ETLツールの選び方を知りたいという方はこちらの「ETLツールとは?選び方やメリットを解説」をぜひご覧ください。
著者