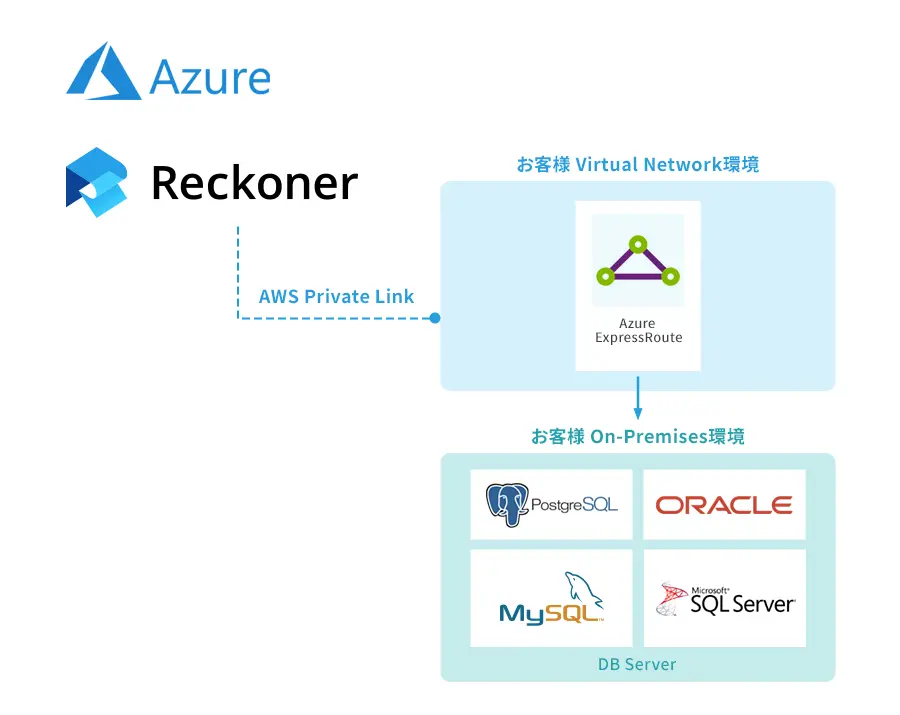
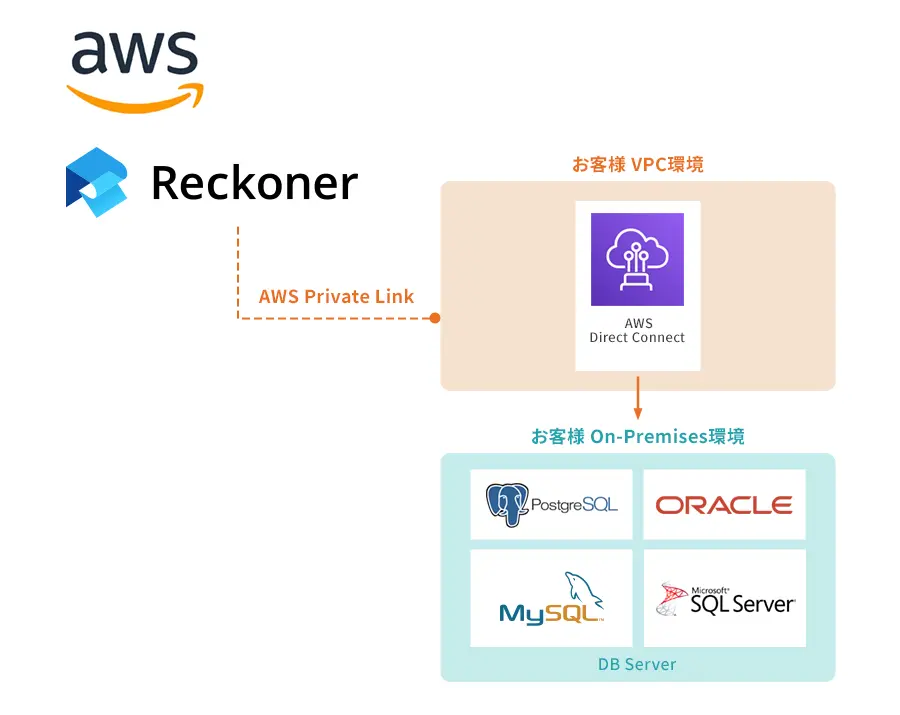
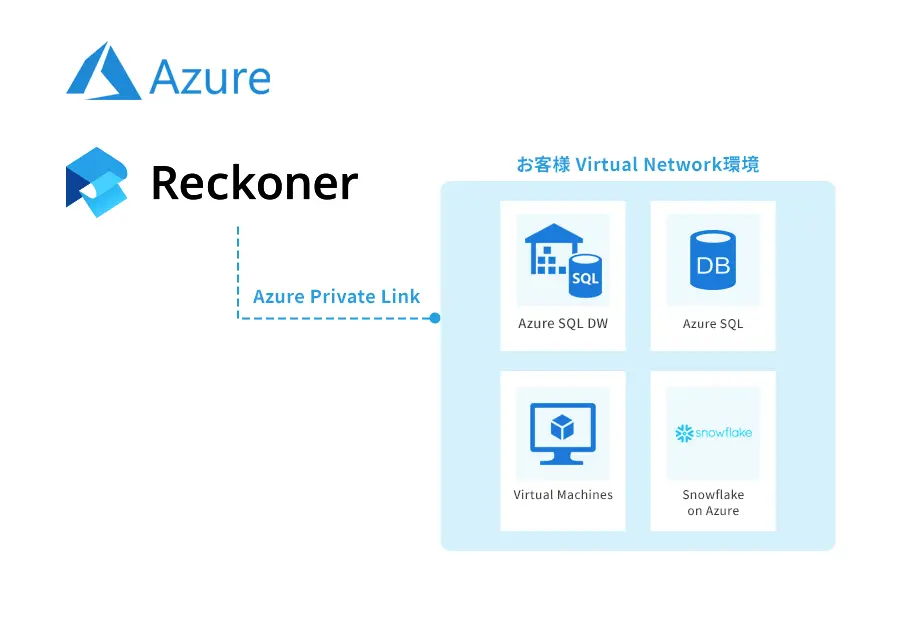
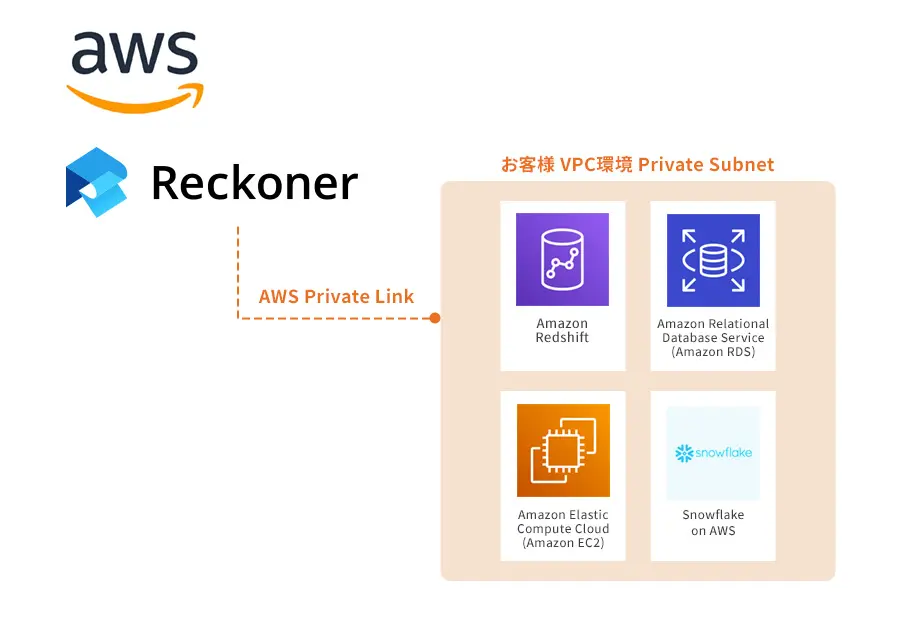
DataOpsツールキットに必要な要素について理解する [相互運用性 | 自動化]
DataOpsツールキットとは、相互運用性と自動化を中核とする補完的なベストオブブリード(各分野で最良のハードウェアやソフトウェアを選択し、その組み合わせでシステム構築を行うアプローチ)のツールの集合体を指します。
では、DataOpsツールキットについて正しく理解するために必要な要素とは何でしょうか。以下で解説します。
なお、下記記事については以下の書籍を参考元とし執筆を行っております。
(参考元:Liam Cleary “Chapter 6. Building a DataOps Toolkit.” In Getting DataOps Right, edited by Palmer, Andy, et al., 43-49. Sebastopol, CA: O’Reilly Media, Inc., 2019)
目次
DataOpsツールキット 1.相互運用性

優れたETLプラットフォームは、相互運用性が基本原則とされています。すなわち、何百ものデータ形式や、多様なプロトコルをサポートするコネクタを利用できるプラットフォームである、ということです。
このため、ETLがサポートできないコネクタを用いるシステム(独自データベース、ERP、CRM、ビジネススイートなど)は、データ統合プロジェクトから除外されます。
- 参考記事:【Webマーケター向け】ETLツールを使ったデータ変換で業務効率化
- 参考記事:マルチクラウドのデータ連携・統合をETLで実現 [手動バッチからの脱却]
- 参考記事:ETLツールが「データのハブ」となる本当のメリット
以下では、相互運用性の観点で、DataOpsツールキットに必要な要素について解説します。
「アジャイル」DataOpsツールキット
変化の大きな昨今において、DataOpsツールキットを作成したとしても、そのツールキットが1年後、2年後、5年後にも有効である保証はありません。DataOpsツールキットも「アジャイル」である必要があります。
「アジャイル」DataOpsツールキットに必要な要素は、異なるベンダー、オープンソース、または自前のソリューション間を用いてツールキットを構成すること、そして特定のツールを入れ替えできること、ツールが適用可能な範囲を自由に変更できることを意味します。
DataOpsツールキットに柔軟性、変更可能性を持たせることで、DataOpsツールキットが長期間にわたり、より効果的な存在であり続けることができます。
データプロファイルの作成
相互運用性を考慮したDataOpsツールキットに含まれる機能には、データ抽出・データ統合ツール、およびデータカタログがあります。なお、データを活用する前に、データプロファイル(データを調査し、作成されたデータのサマリ。データの本格利用前にデータ品質などの問題の把握に利用)を作成します。
- データ抽出ツールは、データソースに直接接続してデータを抽出することで、基本的なデータ品質プロファイルを生成できます。
- データ統合ツールは、抽出したデータプロファイルをインポートし、他ファイルとの比較や検証に用います。
- データカタログツールは、データの意味づけを管理する索引としての要素、データを取得活用するまでの経路を説明する要素があり、データ管理を容易にするメリットがあります。
そして、これらのツールがデータプロファイルのエクスポートとインポートの両方を行うことで、柔軟でコントロールしやすいデータパイプラインを実現できます。
メタデータの交換
DataOpsでは、相互運用性の焦点は、相互運用可能なオープンなメタデータ交換フォーマットの必要性にあります。
データソースからデータ抽出、統合、ダッシュボードへロード、といったフローにおいて、共通のメタデータ交換フォーマットをサポートすることで、各ツールはメタデータを保持できます。
メタデータのパススルーとエンリッチメントは、DataOpsツールの主要な機能であり、DataOpsスタックで相互運用性を実現するため重要な能力となります。
DataOps実践における課題2: 自動化

DataOpsツールキットでは、DataOpsツールはタスクを完全に自動化できる一連のAPIを備えている必要があります。そして、DataOpsタスクは、「継続的自動化」または「バッチ式自動化」を用いて実行されます。
- 連続データの自動化では、ある特定のフェーズ、すなわち既存の状態を更新またはリフレッシュすることのみに関心があります。
- バッチによる自動化では、利用事例の始まり(通常は空またはゼロの状態)、中間、終わりが明確に定義されており、これらの各フェーズで自動化が行われます。
連続データの自動化
DataOpsプロジェクトにおける、連続データの自動化を説明するために、あるデータダッシュボードツールを考えてみましょう。利用するAPI群には、以下が備わっているか確認する必要があります。
- データセット、属性、レコードなどの基本的なデータオブジェクトの更新を可能にするAPIがあるか?
- 新しく利用可能になった属性を使用するために、ダッシュボード自体の定義を更新するためのAPIか?
- ダッシュボードの設定を更新するためのAPIであるか?
- 内部で作成されたオブジェクトと外部で作成されたオブジェクト、または所有するオブジェクトの概念であるか?例えば、同じオブジェクトのユーザによる更新とAPIによる更新の衝突をどのように管理するか?
- 健全性、状態、バージョン、最新性などを報告するためのAPIであるか?
バッチの自動化
バッチによる自動化は、多くの組織において中核となるデータ一括処理です。ここで、あるデータ統合ツールでバッチによる自動化を行う際、必要となる機能を確認しましょう。
- データセット、属性、レコードなどの基本的なデータオブジェクトを作成するためのAPIがあるか。
- 一般的にUIで提供されるアーティファクトをインポートするためのAPIがあるか。例えば、データセットに関するメタデータ、アノテーションや説明、設定、セットアップなど。
- 複雑なユーザーインタラクションやワークフローを実行するためのAPIであるか?例えば、データの操作や変換、マッピング、マッチング、分類など?
- バックアップ、リストア、シャットダウンの状態を報告するためのAPIか?例えば、シャットダウンが可能か、強制的に行わなければならないか、ツールに問い合わせることができるか?
バッチによる自動化は、DataOpsパイプラインの再現性を実現し、新たに公開されるデータセットのエラー率を低く抑えるために重要です。
DataOpsのエコシステムは、特定のベンダーに依存しない、企業、エンジニア、データ運用者などの様々な関係者が関わっていくことでデータ環境が進化していく環境であるといえます。
各組織におけるDataOp環境が発展を遂げていくためには、基本設計において相互運用性と自動化を優先したツールを選択する必要があります。正しいツール選びを行えば、DataOps環境の変化に対応できるはずです。
まとめ
DataOpsツールキットを理解し、あらかじめ準備を行った上で、DataOpsの実践に取り掛かることは、プロジェクトを成功に導くために重要です。
直感的なインターフェースのノーコード型ETLツールであるReckonerは、ノーコードでSaaSとデータ分析基盤統合を実現することができます。DataOpsのツールキットの活用について相談したいことがあれば、お問い合わせください。
また、ETLツールについて詳しく知りたい、ETLツールの選び方を知りたいという方はこちらの「ETLツールとは?選び方やメリットを解説」をぜひご覧ください。